- 原文标题:Row Context and Filter Context in DAX(DAX中的行上下文和筛选上下文)
- 原文网站:SQLBI.com 全世界大名鼎鼎的DAX网站
- 原文地址:https://www.sqlbi.com/articles/row-context-and-filter-context-in-dax/
- 原文更新日期:AUG 17, 2020 UPDATED
- 作者: Marco Russo & Alberto Ferrari
- 本文翻译:喜乐君
译者说明:
在DAX中,存在两种类型的“上下文”(context),context也可以翻译为“环境、背景”,指计算所对应的环境。既可以上计算对应的数据表明细位置,也可以是影响计算值大小的筛选判断。
Context又可以分为两类,一类是“行上下文”,它必然是引用数据表中、特定字段的每一个数据值参与计算,one by one称之为迭代;另一类是“筛选上下文”,它是影响聚合值大小的所有要素,包括聚合的分组字段、聚合的筛选条件等。
这两个概念,是每位学习者理解DAX的难点。
正文开始:
Row Context 行上下文
DAX expressions operate on columns. You would usually write expressions like:
DAX表达式针对于字段列(columns)而运行。通常,你会如下所示写DAX表达式:
Gross Profit := SUMX ( Sales, Sales[Amount] – Sales[TotalCost] )
In the previous expression, Sales[Amount] and Sales[TotalCost] are column references. A column reference intuitively means that you want to retrieve the value of a column. In the example above you would obtain the value of Sales[Amount] for the row currently iterated by SUMX.
在这个表达式中,Sales[Amount] 和 Sales[TotalCost] 代表两个字段列引用。字段列引用,就是指获得该字段中的数据值。在这个例子中,你可以获得Sales[Amount] 和 Sales[TotalCost] 两个字段每一行中的数据值,并在该行中使用SUMX迭代函数完成计算。(这里的重点是the row currently iterated by SUMX)
In addition you can use a column reference to instruct certain functions to perform an action on a column, like in the following measure that counts the number of product names:
另外,你也可以在构建特定函数时引用字段,从而针对该字段完成某些计算动作,比如如下的度量值计算(measure)计算产品名称的数量。
NumOfAllProducts := COUNTROWS ( VALUES ( Product[ProductName] ) )
In this case, Product[ProductName] does not retrieve the value of ProductName for a specific row. Instead, you use the column reference to tell VALUES which column to use. In other words, you reference the column, not its value.
在这个例子中,Product[ProductName] 并非是获得特定行中的数据值;相反,这里是告诉VALUE函数使用哪一个字段列。换句话说,该计算仅仅是引用这个字段列,而非其数据值。
A column reference is a somewhat ambiguous definition because you reference the value of a column in a specific row and the full column itself, both with the same syntax. Nevertheless, DAX expressions are typically easy to read because, although ambiguous, the syntax leads to very intuitive expressions.
“字段引用”是一个比较模糊的概念,因为不管是引用字段列的数据值,还是引用字段列本身,语法都是相同的。然而,尽管“字段引用”模糊,包含字段引用的DAX表达式非常易于理解。
When you use a column reference to retrieve the value of a column in a given row, you need a way to tell DAX which row to use, out of the table, to compute the value. In other words, you need a way to define the current row of a table. This concept of “current row” defines the Row Context.
当你想要在特定行中,引用一个字段的数据值时,你需要一种方式告知DAX表达式获取哪一行完成计算——DAX表达式是在数据表之外的。换句话说,你需要一种方式定义这个表的当前行(define the current row of a table)。 在这里,“当前行”(current row)的概念就是“行上下文”(Row Context)。
You have a row context whenever you iterate a table, either explicitly (using an iterator) or implicitly (in a calculated column):
- When you write an expression in a calculated column, the expression is evaluated for each row of the table, creating a row context for each row.
- When you use an iterator like FILTER, SUMX, AVERAGEX, ADDCOLUMNS, or any one of the DAX functions that iterate over a table expression.
每当你迭代一个数据表,你就会有一个“行上下文”(row context),不管是直接地(比如使用iterator迭代器)还是间接地(比如创建计算列)迭代数据表。
- 当你在“计算列”(calculated columns)中创建表达式时,表达式就会在数据表的每一行中计算,并为每一行创建一个“行上下文”。
- 当你使用迭代器,比如filter、sumX、averageX、AddColumns,或者其他迭代表的任何DAX函数时,也会创建一个“行上下文”。
If a row context is not available, evaluating a column reference produces an error. If you only write a column reference in a DAX measure, you get an error because no row context exists. For example, this measure is not valid:
如果“行上下文”不可用,对字段引用的计算就会出错。如果在DAX度量值中仅仅引用字段(而不做任何其他操作),此时不会生成“行上下文”,因此也会出错。比如,下面的度量值就是无效的。
SalesAmount := Sales[Amount]
In order to make it work, you need to aggregate the column, not to refer to its value. In fact, the correct definition of SalesAmount is:
为了让它生效,你需要为字段引用增加聚合,而非仅仅引用字段的值。销售额总和(SalesAmount)的正确写法应如下:
SalesAmount := SUM ( Sales[Amount] )
Every iterator introduces a new row context, and iterators can be nested. For example, you can write:
每一个迭代器都会创建“行上下文”,并且还可以相互嵌套。比如,
AverageDiscountedSalesPerCustomer :=
AVERAGEX (
Customer,
SUMX (
RELATEDTABLE ( Sales ),
Sales[SalesAmount] * Customer[DiscountPct]
)
)
In the innermost expression, you reference both Sales[SalesAmount] and Customer[DiscountPct], i.e. two columns coming from different tables. You can safely do this because there are two row contexts: the first one introduced by AVERAGEX over Customer and the second one introduced by SUMX over Sales. Moreover, it is worth noting that the row context is also used by RELATEDTABLE to determine the set of rows to return. In fact, RELATEDTABLE ( Sales ) returns the sales of the current customer — by “current” we mean the customer currently iterated by AVERAGEX or, for a more clear definition, the current customer in the row context introduced by AVERAGEX over Customer.
在最里层的表达式中,你引用了两个字段:Sales[SalesAmount] 和 Customer[DiscountPct],它们来自于不同的数据表,分别对应不同的行上下文,前者是对应AVERAGEX的Customer客户表,后者是对应SUMX的Sales销售表。需要强调的是,“行上下文”同时被RELATEDTABLE函数用来决定返回数据集的数量。在这里,RELATEDTABLE( Sales)返回当前客户的销售总和——这里的“当前”意指AVERAGEX迭代器对应的“当前客户”,或者更准确地说,迭代customer客户表的AVERAGEX所生成的“客户”行上下文。
Filter Context 筛选上下文
The filter context is the set of filters applied to the data model before the evaluation of a DAX expression starts. When you use a measure in a pivot table, for example, it produces different results for each cell because the same expression is evaluated over a different subset of the data. The Microsoft documentation describes as “query context” the filters applied by the user interface of a pivot table and as “filter context” the filters applied by DAX expressions that you can write in a measure. In reality, these filters are almost identical in their effects and the real differences are not important for this introductory article. We simply define as “filter context” the set of filters applied to the evaluation of a DAX expression — usually a measure — regardless of how they have been generated.
筛选上下文是在DAX表达式计算之前的、对数据模型的一组筛选条件。比如,在pivot table中使用度量值时,每个单元格之所以会有截然不同的数据结果,是因为相同的表达式实在不同的数据子集中计算的。微软文档中,把来自用户交互界面的筛选条件称之为“查询上下文Query context”,而把写在度量值中的DAX表达式称之为“筛选上下文filter context”。在现实中,这些筛选条件效果基本一致,差异并非明显。把影响DAX表达式计算的筛选都称之为“筛选上下文”,而忽视它们创建上的差异——这里的DAX计算通常是度量值。
For example, the cell highlighted in the following picture has a filter context for year 2007, color equal to Black, and product brand equal to Contoso. This is the reason why its value is different, for example, from the one showing the same year for Fabrikam.
举例来说,下图中被方框突出的单元格,它有一个筛选上下文,由三个要素组成:2007年、黑色、Contoso品牌。这就是它区别于其他品牌,比如Fabrikam的原因。
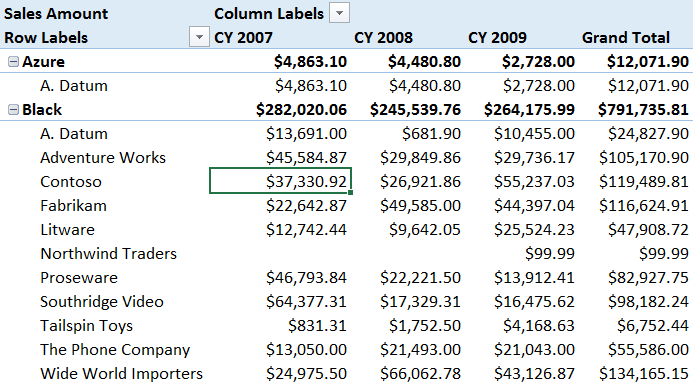
You can obtain the same effect by applying a filter with CALCULATE or CALCULATETABLE. For example, the following DAX query returns the same value as that of the highlighted cell in the previous picture.
你可以使用CALCULATE 或 CALCULATETABLE获得相同的效果。比如,如下的DAX查询可以获得上图中对应单元格的值。
EVALUATE
ROW (
"Sales Amount",
CALCULATE (
[Sales Amount],
'Date'[Calendar Year] = "CY 2007",
Product[Color] = "Black",
Product[Brand] = "Contoso"
)
)
Usually, every cell of a report has a different filter context, which can be defined implicitly by the user interface (such as the pivot table in Excel), or explicitly by a DAX expression using CALCULATE or CALCULATETABLE.
Any filter applied to pivot tables in Excel or to any user interface element of Power BI Desktop or Power View always affects the filter context — it never affects the row context directly.
通常,报表中每个单元格都有一个筛选上下文,这既可以像Excel的透视表一样在用户界面中间接定义,也可以使用CALCULATE or CALCULATETABLE表达式直接定义。
不管是Excel的透视表,还是Power BI Desktop/Power View的任意用户界面的元素,它们生成的筛选都会影响筛选上下文——但它绝不直接影响“行上下文”。
A filter context is a set of filters over the rows of the data model. There is always a filter context for DAX expressions. If the filter context is empty, a DAX expression can iterate all the rows of the tables in a data model. When a filter context is not empty, it limits the rows that a DAX expression can iterate in a data model.
可见,筛选上下文是相对于数据模型明细行的一组筛选条件。对于DAX表达式而言,必然存在筛选上下文。如果筛选上下文为空,DAX表达式会迭代数据模型中数据表的所有明细行(all the rows of tables);反之,如果筛选上下文不为空,它会限制表模型中迭代的数据表明细行(limits the rows)。
Propagation of Filters“跨表筛选”
A row context does not propagate through relationships. If you have a row context in a table, you can iterate the rows of a table on the many side of a relationship using RELATEDTABLE, and you can access the row of a parent table using RELATED.
上下文筛选器不会跨越数据关系。如果你在一个表中有行上下文,你可以使用RELATEDTABLE函数去迭代关系中“多”端一侧数据表的所有明细行,也可以使用RELATED函数获得“一”端(或者称之为“父级”)数据表的明细行。
A filter applied on a table column affects all the rows of that table, filtering rows that satisfy that filter. If two or more filters are applied to columns in the same table, they are considered under a logical AND condition and only the rows satisfying all the filters are processed by a DAX expression in that filter context.
一个数据表中的筛选会影响该表中的所有明细行——仅保留下符合条件的明细行。如果在同一个表中有两个甚至更多个筛选,它们会按照AND(交集)逻辑计算,只有符合所有筛选的明细行才能把DAX表达式进一步计算。
A filter context does automatically propagate through relationships, according to the cross filter direction of the relationship.
筛选上下文会按照交叉筛选方向,自动扩展到关系中的其他表。
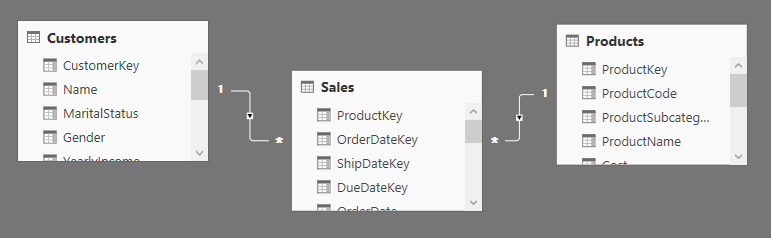
In Power Pivot for Excel, the only direction is one-to-many. A filter applied on the “one” side of a relationship affects the rows of the table on the “many” side of that relationship, but the filter does not propagate in the opposite direction. For example, consider a model where you have two tables, Product and Customer, each with a one-to-many relationship to the Sales table. With a single direction of cross filter, if you filter a product you also filter the sales of that product, but you do not filter the customer who bought those products.
在Excel的power Pivot中,唯一的方向是“一到多”。关系中“一”端数据表的筛选会影响“多”端数据表的明细行,但反之则不行。举例而言,产品Product和客户Customer两个数据表,它们都和Sales销售表由“一对多”的关系。在这个交叉筛选过程中,如果你筛选Product产品表中的某个产品,那么也会筛选该产品对应的销售,但是不能筛选购买该产品的客户。
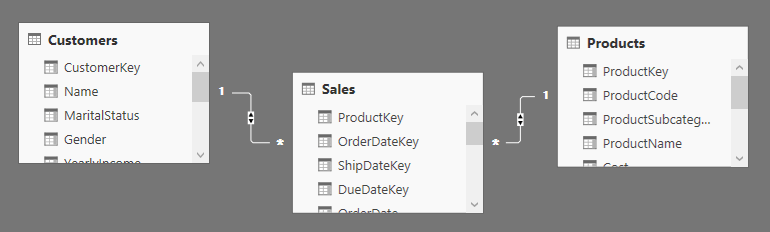
In Power BI Desktop and in SQL Server Analysis Services Tabular 2016, you can enable bidirectional cross filtering. By enabling the bidirectional cross filter, once you filter one table, you also filter all the tables on the “one” side of a relationship. For example, when you filter rows on Product, you implicitly filter Sales and Customer, thus filtering customers who bought the selected products.
在Power BI 和SQL Server Analysis Services Tabular 2016,中,你可以启用双向交叉筛选。此时,一旦你筛选一个数据表,你也可以筛选关系中“一”端的所有数据表。比如,当你筛选Product产品表中的明细行,你间接地筛选了销售表、客户表——即购买过这些产品的客户。
When writing DAX expressions, you can control both the row context and the filter context. Remember that the row context does not propagate automatically through relationships, whereas the filter context does traverse relationships independently from the DAX code. However, you can control the filter context and its propagation using DAX functions such as CALCULATE, CALCULATETABLE, ALL, VALUES, FILTER, USERELATIONSHIP, and CROSSFILTER.
当你写DAX表达式时,你可以控制“行上下文”和“筛选上下文”。记住,行上下文不会自动跨关系延伸到其他表,而筛选上下文则会独立于DAX代码“穿越”关系(traverse relationship)。然后,你可以使用DAX函数来控制筛选上下文及其延伸,比如CALCULATE, CALCULATETABLE, ALL, VALUES, FILTER, USERELATIONSHIP, and CROSSFILTER。
This article is a small example of the complete DAX description you can read in our new book, The Definitive Guide to DAX.
这篇文章是DAX完整介绍的“小样”,大家可以阅读“The Definitive Guide to DAX”(中文翻译《DAX权威指南》高飞译)了解更多内容。
Pingback: 【DAX译文】理解 DAX上下文转换Understanding context transition in DAX - 喜乐君
评论已关闭。