本文写作于2022年4月,发布于微信公众号,近期整理到博客中
随着分析的深入,一个人会越来越敬畏知识、敬畏未知,敬畏前辈的智慧和睿智,与此同时,也对网络标题党深感无聊和拒绝,比如“两周从0到1转行为数据分析师”“年薪百万的分析师体验”之类,虽然它们一直活跃在我的朋友圈和关注的某些公众号中。
抛开商业驱动的因素,这和“以人民之名”鼓励充满热情的年轻人投身官场,最后却把他们染成五颜六色以至于失去自我,有什么区别呢?
喜乐君最近在重写《数据可视化分析:Tableau原理与实践》一书,之所以“重写”,而非“修订”,是因为过去两年读书学习、企业实践,让我充分地感受到了自己的知识盲区是如此之大,我的书已经很难通过小修小补达到我所期待的完美——我不仅仅是想写一本书,我想分享有价值的知识给后来者。
今日,仅以“筛选filter”为例。
在2020年7月首印的《数据可视化分析:Tableau原理与实践》书中,我把筛选放在第五章,和可视化、格式调整放在一起,当时觉得筛选很easy,不足以另立章节。不过,随着后来几次加印调整,到写作《业务可视化分析》一书时,我已经感受到了自己之前的无知。
筛选是最基本的交互方式,从交互的角度看,它是如此庞大的体系,堪比数据准备、计算逻辑。我过多地强调了Tableau操作方面的新功能“参数动作“”集动作“,但却没有针对它的底层逻辑展开说明,这导致多个筛选、筛选优先级等问题上阻力重重。因此在《业务可视化分析》中,我单独列了一章(第13章),把它和结构化分析并列,从而帮助读者理解,交互和结构分析在探索分析中都至关重要,不可偏废。
这次重写图书,借助于SQL的知识,我得以更深入地理解交互筛选背后的逻辑,并努力用更加清晰的知识框架理解。
我的目标很明确,让初学者能从一而终,让高手能获得体系性的启发,从而举一反三。
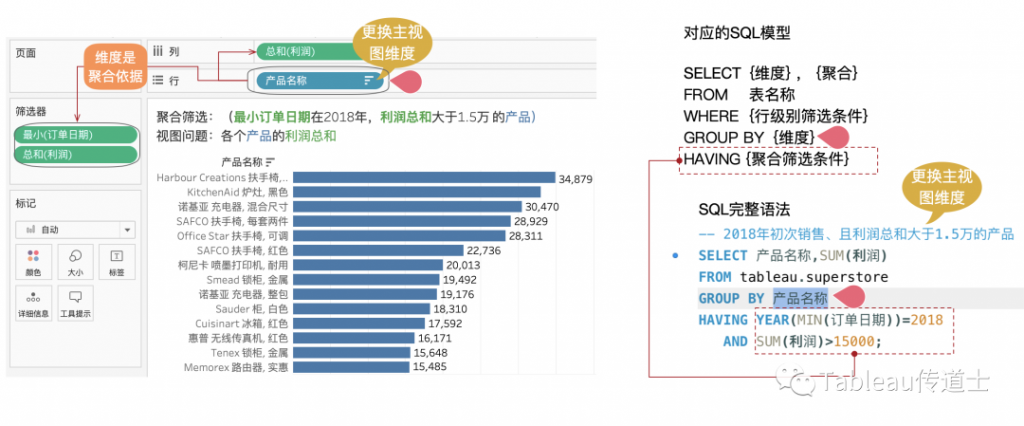
02—筛选与SQL查询
今年年初读了SQL的书,我被它的逻辑之简洁所震撼,常用的查询语法不过几十个关键词,却能组合出任意的美妙数据世界。这种简洁的能力,绝对值得再传播五十年。
起初,我以为SQL的筛选就是where和having,结合Tableau才知道,筛选作为一个查询的一部分,并非对应特定的语法功能,而是对应特定的数据集操作,所以join才是高级分析中的筛选大王。
简单的筛选是字段的筛选;
高级的筛选是数据集的计算。
理解了这个部分,就往前迈出了一大步。

在高中数学中学习过“集合论”,那时只知道考卷中小明、小王这样的组合关系,如今才知道“集合”所代表的数据关系,乃是最普遍的数据集。两个数据集就有上述如此之多的相互关系,万一问题中有三个样本范围条件呢?
筛选的关键就不是单个数据表中字段判断这么简单。
也正为此,高级的数据筛选,就和数据准备中的数据关系(join连接或者relationship关系匹配)衔接在了一起。高级分析师可以借助于Tableau和SQL的对比,完整理解它们的关系,以此作为自己通透理解的明证。

如果往后看呢?筛选的本质是什么?
02—筛选的本质
筛选即判断,判断即计算。
筛选中最容易迷惑的是“多个筛选的优先级”,这个问题的本质则是计算的先后关系。因此,筛选又是计算的一个特殊应用。
在这次重写图书时,我终于完成了自己一直想绘制的一个关系图:
筛选和计算的优先级既然筛选都是计算,计算是有层次先后的,那么筛选也就可以与之相对而生。因此,我在下图中,左侧代表计算,右侧代表筛选,自上(数据源)而下(视图)代表它们的先后关系。

当然,要完整地理解这个内容,就要进一步理解计算的类型、筛选的类型,多个筛选的组合情景等内容。至此,是不是发现就像开了一扇通往无穷世界的窗户?

恰逢筛选章节完成之际,特此分享,以求“教学相长”。
了解 喜乐君 的更多信息
订阅后即可通过电子邮件收到最新文章。