半年之后,作者重新修正本文,
【喜乐君按】作为BI工具的两大巨擘,Tableau和Power BI都拥有相当的用户和粉丝,很多人非常关心二者的区别,于是就有了喜乐君“Power BI向左、Tableau向右”的对比系列。本文最早写于2023年春节,6个月之后,补充修正,并作为“Tableau VS Power BI”对比系列的重要组成部分。
- 如何选择BI工具:Power BI“向左”,Tableau“向右”
- BI产品对比:CALCULATE vs. LOD表达式 (本文)
本文最早发布在“Tableau传道士”,文章:https://mp.weixin.qq.com/s/ALxtB5IqGYv2fRudVjvc1Q
LOD表达式是Tableau产品具有划时代意义的关键产品,自从9.0版本发布以来,至今依然被分析师津津乐道;而CALCULATE表达式则是Power BI“创建度量值”生成的表达式。从技术上看,二者都是分析函数发展的里程碑,只是方向截然不同——LOD走向了多个“详细级别”的多维分析,CALCULATE走向了多重筛选条件,并发展了CONTEXT和CONTEXT Transition一系列概念。
为了帮助理解CALCULATE表达式,本文从Excel中的SUM+IF和SUMIF说起。
一、从SUM+IF到SUMIF:间接筛选和直接筛选
在2022年写作《数据可视化分析2.0》(京东已经发布 2023.9)的过程中,我补充了很多之前的知识盲区,特别是指标分类(metric)和条件计算(conditional calculation)。分析的本质过程是聚合,聚合度量的业务形态则是指标,指标的难点在于与外部条件的组合。因此,指标因计算的复杂度不同而有了抽象度差异,常见的几个类型如下:
- 一类指标:直接聚合,如 销售额总和
- 二类指标:聚合的二次计算,如利润率(利润总和/销售额总和)
- 三类指标:包含筛选条件的聚合及其比较,如MTD销售额、YTD销售额、MTD销售额同比 (聚合前面指标了筛选范围)
- 四类指标:“钻石客户数量”:其中“钻石客户为累计间夜60+且积分10万+”(在筛选条件基础上增加预先聚合)
从计算的复杂性来看,第三类及之后的类型是难点,也是大数据计算的性能“陷阱”,比如消费金融的LOSS%、C-M1、M2+@MOB0-6这样的指标体系。特别是一个问题同时包含了多个此类指标,不同计算的方式就有了天壤之别的性能差异。比如:
2022年,各个类别、子类别 的 YTD销售额(总和)及其同比、MTD销售额及其同比、利润率
在很长一段时间中,我误以为只有一种“条件计算”的逻辑,就是SUM+IF,殊不知在Excel及其体系中,还有一个性能优化方案——SUMIF方案。基于SUMIF才能更好地理解CALCULATE表达式的精髓——千变万化,不离其宗。
1、SUM+IF:用修改数据的方式间接实现筛选
先说最易于理解的方案:SUM+IF,对符合IF条件的数据行聚合相加。以“Florida州的销售数量总和”为例,初学者使用Excel、SQL和Tableau会用如下的计算实现。
- 透视表的逻辑:筛选和聚合相互独立
分析的本质是聚合,聚合对应Excel的透视表、SQL的分组聚合(group by)、BI工具的视图。因此,在Excel中,标准的做法是基于数据表明细行创建透视表,然后将“Quantity”和“State”依次拖入“值”和“筛选器”区域之中。如下所示:
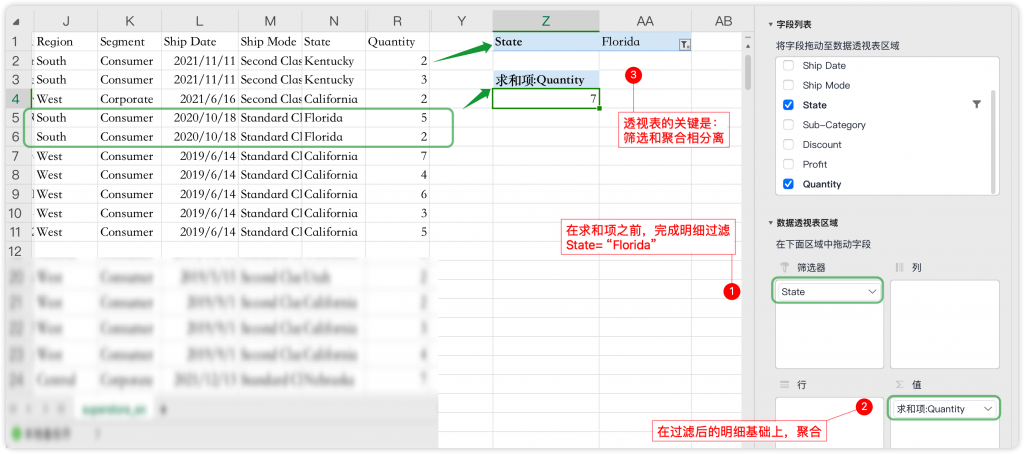
透视表天然是把筛选条件和聚合相互独立的。独立的好处是性能更好,但在包含不同范围的问题中会损失一些灵活性。比如“东北地区,各品牌的当年销售额、上年销售额及同比”,由于多个度量值对应不同的范围,此时透视表的“筛选器”就难以区别对待。于是,更具有灵活性的SUM+IF组合就出来“救场”了。
- Excel SUM+IF,条件判断和聚合完全独立,按照从内到外次序分别计算
一定要分开处理,这里先用IF做一个辅助列(即DAX中的计算列),然后再使用透视表对辅助列做聚合。
举例说明,计算“Florida州的销售数量”。可以先使用IF做一个辅助列,把满足条件的Quantity标记出来,然后在透视表中将其聚合,这样就在不是用单独的筛选器前提下,完成了“Florida州销售数量总和”计算。究其本质,是将筛选作为了聚合值的一部分。它不是真正意义上的筛选,而是通过“篡改数据值”的方式,让不符合条件的数据值随被聚合、但等同没有。

需要补充说明的是,这里“IF判断是在数据表明细行完成的”,而聚合过程,是在“透视表阶段”完成的。到了DAX,某些专家为它们赋予了Row CONTEXT和FILTER CONTEXT的名字,结果搞晕了很多人。
当然,强调要分开计算,是为了避免与下面这种明细表中一次性计算的方法相区分。 如果在明细行中使用SUM+IF的计算,每个单元格使用如下的判断,则相当于在数据表明细行中完成“Florida的销售数量”计算,行级别+IF+聚合,结果会在每一行上有有意义,但又具有了透视表的聚合结果!
=SUM( IF(N:N="Florida",R:R,0) )如果你能理解这里,贡献你,你已经理解了Power BI和DAX中最为烧脑的题目之一——“在计算列中使用聚合”。

当然,既然有前面(1)辅助列、(2)透视表的基础,我们也可以把上面的(3)行级别聚合结果,视为是透视表 Vlookup到明细表中的数据合并形式。只是目前的这种理解容易把问题复杂化,因此这里暂且按下不表。
2、SQL和Tableau中的SUM+IF形式
SQL SUM+IF:
SELECT SUM( IF (YEAR([订单日期])=2022, [销售额], null ) as YTDFROM table Tableau SUM+IF:
SUM( IIF (YEAR([订单日期])=2022, [销售额], null )在上述三个方法中,SUM和IF借助于括号嵌套而结合在一起,IF优先于SUM。由于SUM和IF完全独立,从计算的角度看,SUM对不符合计算条件的null或者0值也要执行相加计算——这一点非常重要,后面SUMIF的优化方案就是从这里而来。
在《数据可视化分析2.0》第六章筛选章节,我补充了“独立筛选和计算条件筛选”这两个类型,前者对问题中的所有指标起作用,后者仅对与之结合的聚合起作用;前者是性能的积极因素,后者通常则是消极因素——不同的优化能力,体现了分析师、工具之间的差异。在这一点上,近似编程的DAX确实是更胜一筹,其次是高级灵活的SQL,不过二者都需要理解原理、技能卓越的分析师才能发挥最大价值。
如何优化SUM+IF的计算性能呢?
很久之前,Excel、SQL都给出了方案,只是业务用户不好察觉,这种区别于SUM+IF的形态,我通称之为SUMIF方案——虽然IF依然先于SUM计算,但却不再独立,而是紧紧结合在一起。
理解SUMIF相对于SUM+IF的优化特征,是理解Tableau和PBI的方向性不同,特别是理解Calculate表达式(聚合表达式+filter过滤条件)的关键。
3、SUMIF优化方案:独立于聚合之外的直接筛选
SUM+IF之所以慢,不在于IF返回的结果是0还是null,关键在于聚合计算需要遍历、依次访问数据表的每一行(PBI中称之为迭代iterate,以后单独介绍)。对于动辄几百万、上千万的数据而言,遍历整个表会消耗很多的算力资源,对于结果却毫无用处。
我在2021年5月写过一篇博客,题名“【高级】Tableau性能优化之关键:两种计算对性能的影响实证”,介绍过不同的筛选方法对性能的巨大影响。上述SUM嵌套IF的方式就是影响大数据性能的关键场景之一。
也许是这个原因,Excel就有了一个SUMIF函数,看上去它只是SUM和IF的组合形式,但是从聚合角度看,它优化了计算逻辑,跳过了不符合条件的数据行。
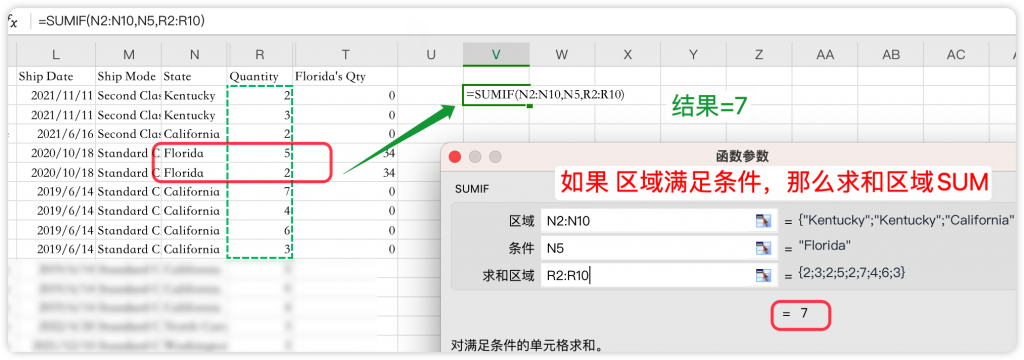
大家可以用如下的图示理解SUM+IF和SUMIF之间的区别:
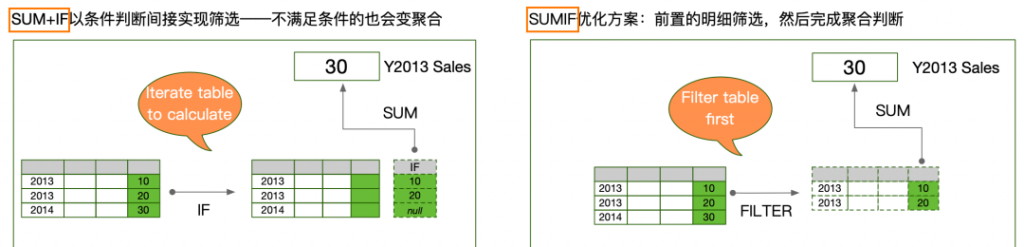
虽然二者条件完全相同,但是SUM+IF中的SUM要对数据表的所有行执行聚合(iterate the table and then aggregate),因此消耗大量无效算力;而SUMIF只对符合条件的有限数据行执行聚合(iterate the table, filter rows and then aggregate),避免了算力浪费。
如果把上面的3行数据扩展到3000万行,性能之间的巨大差异往往会导致数据库资源长期占用,甚至拖垮一个分析工具。当然,除了Excel,SQL也有完全相同的逻辑,它是借助于WHERE把条件前置到GROUP BY和SUM聚合之前。上述“2022年的销售额总和”,就有了第二种写法:
- SQL SUMIF:
SELECT SUM( [销售额] )FROM tableWHERE YEAR([订单日期])=2022这个问题非常简单,没有分类字段、指标单一;如果是如下的复杂的问题,SQL中还要实现上述的SUMIF效果,就需要一个全新的功能——嵌套聚合查询。
2022年,各个类别、子类别 的YTD销售额(总和)、MTD销售额、利润率
可以如下实现(MTD简化为2022年12月):
SELECT a.类别,a.子类别
SUM( a.[销售额] ) as YTD sales,
FROM table a
JOIN
(SELECT b.类别,b.子类别,
SUM( b.[销售额] ) as MTD sales,
FROM table b
WHERE YEAR(b.[订单日期])=2022 and MONTH(b.[订单日期])=12
GROUP BY b.类别,b.子类别
) on a.类别 = b.类别,a.子类别=b.子类别
WHERE YEAR([订单日期])=2022
GROUP BY a.类别,a.子类别在上述的SQL查询中,每一个SUM都没有和IF直接组合,而是皆有嵌套子查询的WHERE筛选完成条件筛选,WHERE优先于分组聚合,因此有助于优化性能,这样就实现了下图中右侧的计算方案。当然,我对SQL所知尚浅,应该还有其他类似、甚至性能更优的方案。
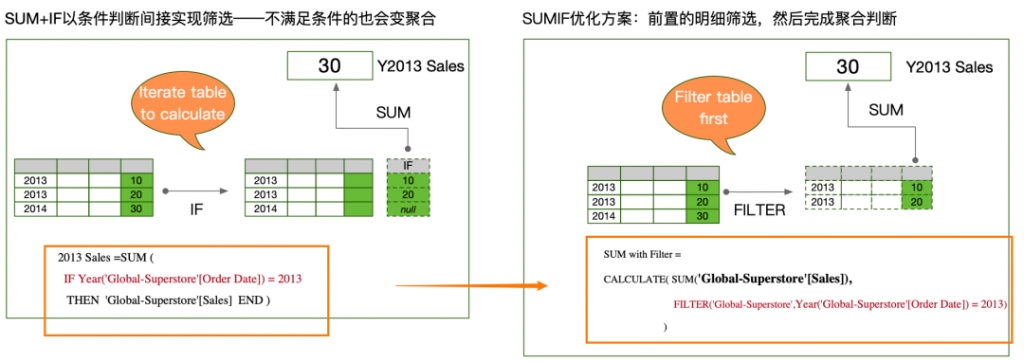
理解了上述EXCEL、SQL的过程,就可以轻松地理解,为什么DAX设计了一个专门的CALCULATE表达式,并且把FILTER条件置于其中,从而构成了如下的表达式语法。
CALCULATE(聚合表达式, FILTER条件)通过在每一个度量中单独指定filter计算条件,DAX可以在引擎中将其优先级提前,从而避免了SUM+IF的低下性能;同时,又保留了SUM+IF相比透视表筛选器所具有的灵活性,可为一举两得。也正因为此,我个人通常把CALCULATE称之为表达式(expression),而非函数(function),强调它两个功能组合而来、用于完成特定分析需求。
下面内容,准备拆分出来(Sep 7, 2023)
二、CALCULATE和LOD的差别
从计算的角度看,CALCULATE表达式确实代表了极高的逻辑水平,它为优化大数据性能提供了一个绝佳方案,是大数据分析的代表作。它在POWER BI中的位置,犹如LOD之于Tableau。
二者的共同点是,产品经理总结了分析中高频的分析需求,然后将其封装为不同的函数。只是Tableau向左——把维度分类字段封装到FIXED表达式中,而POWER BI向右——把筛选条件封装到CALCULATE表达式中。
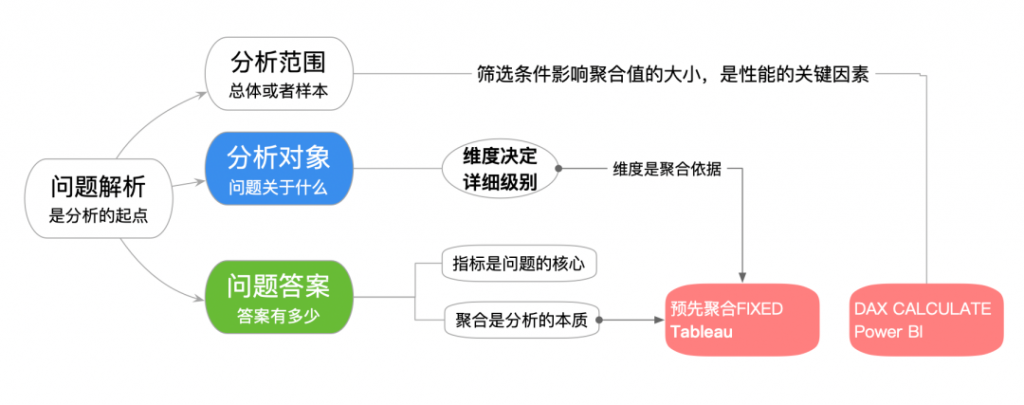
因此,LOD解决了不同详细级别的问题合并的问题,CALCULATE解决了不同范围的指标(度量值)的计算优化问题。
不管是何种语法,前端的表达式都将转化为数据库层面的SQL查询,因此从SQL的角度看二者的共同点,二者都是嵌套查询(nested query)和数据合并(join)的组合形式。
不过,从业务的角度看,Tableau 的LOD表达式有助于回答“多维分析”的问题,典型代表是RFM分析,以及我个人钟爱的购物篮关联分析(你很难找到更好的方案);而Power BI的Calculate解决的是筛选的问题,它引出了一个难点,如何调节calculate内部筛选(internal filters)和视图中外部筛选(external filters)的关系,于是就有了ALL、ALLexcept等多个调节符,考虑到Power Bi把筛选条件和分类维度都视为filter context,这一逻辑影响了业务用户理解问题中的层次关系。
也正因此,我个人之见,Tableau是业务方向的,Power BI是技术方向的。
那些努力模仿、学习,并试图超越它们的国产BI工具,至少应该先思考自己的方向,然后再有针对性地借鉴,特别是理解不同技术路线给业务带来的负面性,才能完成超越。
当然,从目前的情况看,我们还在“摸石头”,只知其表,未达其里,更何谈过河呢。
新年喜乐平安@喜乐君
癸卯年正月初三
Sep 7, 2023 V2.0 大幅度修正本文,强化透视表、SUM+IF、SUMIF的逻辑连贯性